От концепта Data Warehouse к Data Lakehouse
Последнее время в аналитике данных становится популярна концепция Data Lakehouse.
Чем же она отличается от предыдущих популярных концепций Data Warehouse и Data Lake (“Озеро данных”)?
В этой статье попытаемся раскрыть этот вопрос.
Сравнение концептов
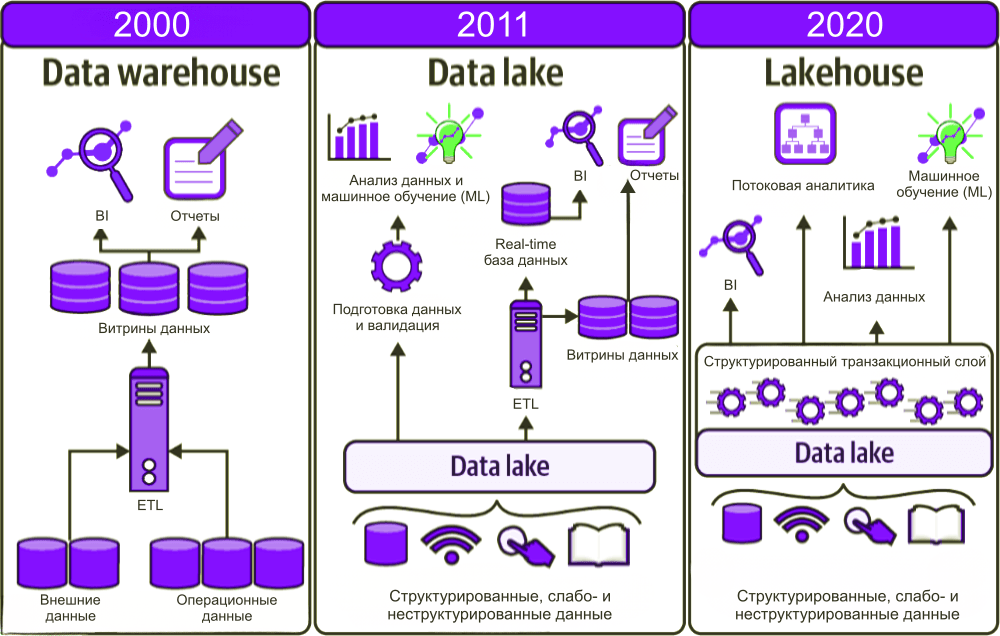
Таблица ниже даёт общее представление о различиях между этими тремя концепциями:
| Критерий | Data Warehouse (DWH) | Data Lake | Data Lakehouse |
|---|---|---|---|
| Основная цель | Хранение и анализ структурированных данных для бизнес-аналитики. | Хранение больших объемов структурированных, полуструктурированных и неструктурированных данных. | Комбинация возможностей Data Warehouse и Data Lake для хранения и анализа данных различных типов. |
| Типы данных | Преимущественно структурированные данные (таблицы, схемы). | Структурированные, полуструктурированные и неструктурированные данные (текст, видео, изображения). | Структурированные, полуструктурированные и неструктурированные данные. |
| Структура данных | Строгая схема (Schema-on-write), данные должны соответствовать определенной структуре перед загрузкой. | Отсутствие строгой схемы (Schema-on-read), данные можно загружать без предварительной обработки. | Гибкая схема (Schema-on-read или Schema-on-write), поддержка как структурированных, так и неструктурированных данных. |
| Обработка данных | Батч-обработка (Batch Processing), ETL (Extract, Transform, Load). | Потоковая и батч-обработка, ELT (Extract, Load, Transform). | Поддержка как батч-, так и потоковой обработки, гибкость в выборе подхода к обработке данных. |
| Скорость выполнения запросов | Высокая скорость запросов благодаря оптимизации для аналитических операций. | Низкая скорость запросов из-за необходимости преобразования данных при чтении. | Улучшенная скорость запросов по сравнению с Data Lake за счет использования метаданных и индексации. |
| Масштабируемость | Ограниченная масштабируемость, требует значительных усилий для расширения. | Легко масштабируется для работы с большими объемами данных. | Легко масштабируется, сохраняя при этом производительность запросов. |
| Использование хранилища | Используется дорогое хранилище для структурированных данных. | Используется недорогое хранилище для всех типов данных. | Используется недорогое хранилище с возможностью эффективного управления данными. |
| Поддержка аналитики | Поддерживает сложные аналитические запросы и OLAP (Online Analytical Processing). | Поддерживает базовую аналитику, но требует дополнительной обработки данных для сложных запросов. | Поддерживает как простые, так и сложные аналитические запросы, включая машинное обучение. |
| Примеры технологий | Oracle, Microsoft SQL Server, Amazon Redshift, Google BigQuery. | Hadoop, Apache Spark, AWS S3, Azure Data Lake. | S3, Trino, Apache Iceberg. |
Концепция Data Lakehouse объединяет преимущества Data Warehouse и Data Lake , создавая гибкую и эффективную платформу для работы с данными. Давайте рассмотрим, как именно Data Lakehouse интегрирует лучшие черты обоих подходов:
1. Гибкость в хранении данных (от Data Lake)
- Поддержка различных типов данных : Как и в Data Lake, Data Lakehouse позволяет хранить структурированные, полуструктурированные и неструктурированные данные. Это означает, что вы можете загружать любые данные — от традиционных таблиц до файлов JSON, изображений, видео и потоковых данных — без необходимости их предварительной обработки.
- Схема на чтение (Schema-on-read) : В отличие от строгой схемы в Data Warehouse (Schema-on-write), где данные должны соответствовать определенной структуре перед загрузкой, в Data Lakehouse можно использовать схему на чтение. Это позволяет загружать данные без предварительного определения структуры, что упрощает процесс интеграции новых источников данных.
2. Производительность запросов и аналитика (от Data Warehouse)
- Оптимизация для аналитики : Data Lakehouse сохраняет высокую производительность запросов, характерную для Data Warehouse. Он использует технологии, такие как ACID-транзакции (атомарность, согласованность, изоляция, долговечность), которые обеспечивают надежное выполнение операций чтения и записи. Это особенно важно для аналитических задач, требующих быстрого доступа к данным.
- Индексация и метаданные : В Data Lakehouse используются механизмы индексации и управления метаданными, которые ускоряют выполнение сложных запросов. Эти механизмы позволяют быстро находить нужные данные и выполнять аналитические операции, что делает работу с большими объемами данных более эффективной.
3. Масштабируемость и управление затратами (от Data Lake)
- Масштабируемость : Data Lakehouse наследует масштабируемость Data Lake. Он может легко работать с огромными объемами данных, добавлять новые источники данных и расширять хранилище по мере роста бизнеса. Это достигается за счет использования недорогих хранилищ данных, таких как Amazon S3 или Azure Blob Storage.
- Эффективное использование ресурсов : В отличие от Data Warehouse, который часто требует дорогостоящего оборудования и лицензий для поддержания производительности, Data Lakehouse использует недорогое хранилище и облачные ресурсы, что снижает общие затраты на хранение и обработку данных.
4. Единая платформа для всех пользователей (объединение концепций)
- Объединение аналитиков и разработчиков : В Data Lakehouse могут работать как бизнес-аналитики, так и специалисты по данным. Аналитики могут использовать традиционные инструменты для выполнения SQL-запросов и создания отчетов, а разработчики могут работать с данными через API и языки программирования, такие как Python или Scala.
- Универсальность : Data Lakehouse предоставляет единую платформу для выполнения различных задач: от простых аналитических запросов до сложных моделей машинного обучения. Это устраняет необходимость в использовании нескольких систем для разных типов анализа, что упрощает управление данными и повышает эффективность работы.
5. Технологии, поддерживающие Data Lakehouse
- Delta Lake : Delta Lake — это одна из ключевых технологий, которая поддерживает концепцию Data Lakehouse. Она обеспечивает ACID-транзакции, версионирование данных и эффективное управление метаданными, что позволяет сочетать преимущества Data Lake и Data Warehouse.
- Apache Iceberg : Apache Iceberg также является популярным решением для реализации Data Lakehouse. Он предоставляет возможности управления метаданными, индексации и транзакций, что делает его идеальным выбором для создания гибких и масштабируемых платформ для работы с данными.
- Databricks Lakehouse Platform : Databricks предлагает собственную платформу Lakehouse, которая объединяет возможности Spark для обработки больших данных с возможностями управления метаданными и индексации, что позволяет эффективно работать с различными типами данных и выполнять сложные аналитические задачи.
Примеры применения
- Машинное обучение и анализ данных : В Data Lakehouse можно хранить сырые данные и одновременно выполнять сложные аналитические запросы и модели машинного обучения. Это позволяет комбинировать различные источники данных и получать более точные результаты.
- Потоковая обработка данных : Data Lakehouse поддерживает как батч-обработку, так и потоковую обработку данных, что делает его идеальным решением для работы с реальными данными в режиме реального времени.
Как итог, Data Lakehouse объединяет лучшие черты Data Warehouse и Data Lake , предоставляя универсальную платформу для работы с данными. Он позволяет хранить и обрабатывать любые типы данных, обеспечивает высокую производительность запросов, масштабируется для работы с большими объемами данных и при этом остается экономически эффективным.
От DWH к Lakehouse
Если вы уже внедрили и используете концепт Data Warehouse, то вы можете рассмотреть переход сразу к Data Lakehouse. Какие аспекты помогут правильно понять целесообразность такого перехода? Рассмотрим ниже.
1. Гибкость в работе с различными типами данных
- Проблема DWH : Традиционные Data Warehouse оптимизированы для работы со структурированными данными (например, таблицами в базах данных). Они не поддерживают эффективное хранение и обработку полуструктурированных (JSON, XML) и неструктурированных данных (файлы изображений, видео, текстовые документы).
- Решение Data Lakehouse : Используя такие хранилища, как Закрома.Хранение (S3) , позволяет хранить и обрабатывать все типы данных — структурированные, полуструктурированные и неструктурированные. Это расширяет возможности анализа, позволяя интегрировать данные из различных источников, таких как социальные сети, датчики IoT, логи серверов и многое другое. Использование S3 обеспечивает гибкость и масштабируемость, так как это недорогое и высокопроизводительное хранилище.
2. Улучшенная производительность и масштабируемость
- Проблема DWH : Традиционные Data Warehouse часто сталкиваются с проблемами масштабирования при увеличении объема данных. Они могут быть дорогими в обслуживании и требуют значительных усилий для настройки и оптимизации.
- Решение Data Lakehouse : использовать объектное хранилище данных (S3) , что позволяет легко масштабировать систему по мере роста объема данных. Более того, использование технологий, таких как Apache Iceberg, обеспечивает высокую производительность запросов благодаря индексации, метаданным и ACID-транзакциям. S3 предоставляет возможность хранения огромных объемов данных без необходимости в сложной и дорогостоящей инфраструктуре.
3. Снижение затрат на управление данными
- Проблема DWH : Поддержание традиционного Data Warehouse может быть дорогостоящим из-за необходимости использования специализированных серверов и лицензий на программное обеспечение. Кроме того, процесс ETL (Extract, Transform, Load) может быть сложным и трудоемким.
- Решение Data Lakehouse : используется недорогое хранилище данных, такое как S3, что значительно снижает затраты на хранение и обработку данных. Использование гибридного S3-хранилища Закрома.Хранение позволяет минимизировать капитальные затраты на оборудование и уменьшить операционные расходы за счет оплаты только за фактически использованное пространство и трафик. Кроме того, использование ELT (Extract, Load, Transform) вместо ETL позволяет минимизировать усилия по подготовке данных перед загрузкой в систему, что также снижает затраты на управление данными.
4. Поддержка реального времени и потоковой обработки данных
- Проблема DWH : Традиционные Data Warehouse обычно оптимизированы для батч-обработки данных, что означает, что они не всегда могут эффективно работать с потоковыми данными в режиме реального времени.
- Решение Data Lakehouse : поддерживает как батч-, так и потоковую обработку данных, что позволяет выполнять анализ в режиме реального времени. Использование S3 в сочетании с современными технологиями, такими как Apache Spark или Flink, обеспечивает возможность обработки данных в режиме реального времени с минимальными задержками. Это открывает новые возможности для бизнеса, таких как мониторинг операций в реальном времени, быстрая реакция на изменения рынка и повышение конкурентоспособности компании.
5. Улучшение совместной работы между аналитиками и разработчиками
- Проблема DWH : В традиционных Data Warehouse аналитики и разработчики часто используют разные системы и инструменты, что создает барьеры для совместной работы и замедляет процесс анализа данных.
- Решение Data Lakehouse : Data Lakehouse предоставляет единую платформу, которая поддерживает различные способы взаимодействия с данными. Аналитики могут использовать SQL для выполнения аналитических запросов, а разработчики могут работать с данными через API и языки программирования, такие как Python или Scala. Использование S3 в качестве основного хранилища данных позволяет легко интегрировать различные инструменты и технологии, устраняя необходимость в использовании нескольких систем и упрощая совместную работу между различными командами.
Заключение
Переход от традиционного Data Warehouse к Data Lakehouse , использующему S3-хранилище, такое как Закрома.Хранение, открывает новые горизонты для работы с данными. В новом концепте S3 обеспечивает гибкость, масштабируемость и экономичность, что делает его идеальным выбором для современных организаций, стремящихся к инновационному анализу данных и повышению своей конкурентоспособности. Эти преимущества делают Data Lakehouse мощным решением для управления и анализа больших объемов данных различных типов.