Объектное хранилище S3: что это такое и зачем нужно бизнесу
В мире ежедневно производится 329 млн терабайт данных. Это сообщения, изображения, видео и аудио, финансовые транзакции, поисковые запросы и многое другое — данные, которые нужно где-то хранить, обогащать и анализировать. Согласно исследованию, проведенному K2 Cloud и Arenadata, объемы данных, обрабатываемых российскими компаниями, растут на 25–30% в год. И это не просто цифры, за каждой записью стоят реальные процессы, отчёты, клиентские данные, критические системы. Традиционные серверные комнаты и NAS перестают справляться: чтобы добавить ещё пару терабайт, приходится менять диски, резервировать данные, бороться с упавшей производительностью.
На этом фоне термин «S3» стал синонимом другого подхода к хранению неструктурированных данных. Но что именно означает «S3 хранилище», почему этот термин превратился в стандартную формулу, и когда бизнесу действительно стоит смотреть в сторону объектных хранилищ? Эта статья — для IT-руководителей, архитекторов и владельцев бизнеса, которым нужно принять взвешенное решение, понимая не только преимущества, но и ограничения технологии.
Почему S3 стало стандартом
Когда Amazon в 2006 году представила Simple Storage Service (S3), это был облачный сервис с набором REST-операций для загрузки, получения и удаления файлов («объектов»). Со временем способ работы с объектами, набор HTTP-команд и модель взаимодействия стали настолько удобны и широко распространены, что «S3» перестало быть только именем сервиса и превратилось в де-факто протокол — набор ожиданий, который поддерживают десятки облачных и локальных решений. Сегодня десятки облачных и локальных решений называют себя «S3-совместимыми» — то есть поддерживают API, принятый в объектном хранилище S3 (операции PUT, GET, DELETE, LIST, версии, lifecycle-правила и политики доступа).
Термин S3 стал таким же нарицательным, как ксерокс, термос и аспирин, и из названия конкретного сервиса стало названием способа организации хранения.
Ключ в том, что S3 — это не конкретный продукт, а способ работы с данными (API спецификация), который поддерживают десятки решений. Именно это делает возможным смену провайдера без переписывания бизнес-логики и формирует экосистему инструментов вокруг стандартизированного интерфейса.
Файловое, блочное и объектное хранилище: три разных подхода
Чтобы понять, почему S3 эффективен в одних задачах и неэффективен в других, полезно вернуться к базовым моделям хранения данных. Традиционно говорят о трёх крупных парадигмах: файловое, блочное и объектное хранение.
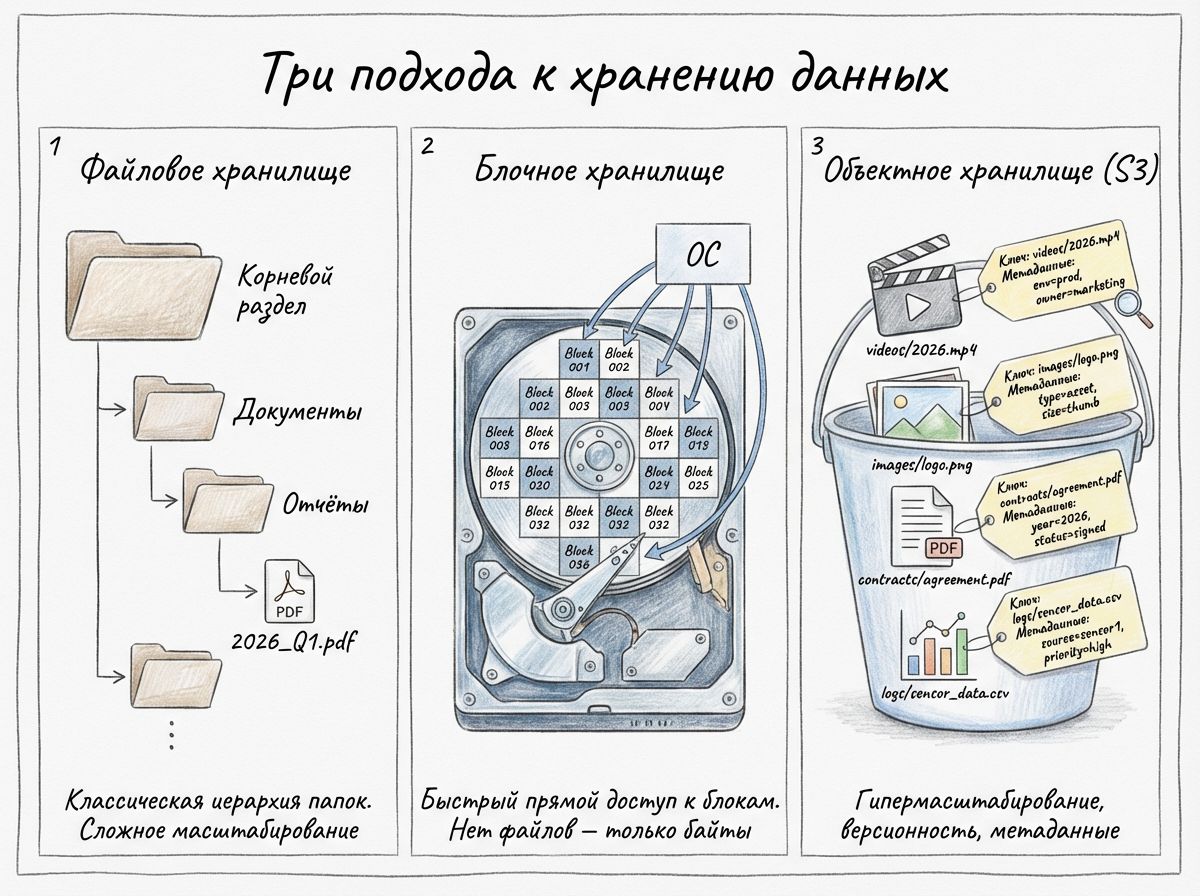
Файловое хранилище опирается на знакомую всем иерархию папок и протоколы вроде NFS и SMB. Оно удобно для совместной работы, для сетевых дисков и пользовательских каталогов — там, где нужна POSIX-семантика и операции над файлами и папками в привычном виде. Но масштабирование файловой системы выше нескольких десятков терабайт становится дорогим и сложным: появление метаданных, блокировок, часть операций становятся узкими местами при высокой конкуренции доступа.
Блочное хранение представляет собой модель, где данные разбиваются на блоки и назначаются виртуальным дискам. Эта модель обеспечивает высокую производительность и низкие задержки, что критично для баз данных и виртуальных машин. Но блочное хранение не предназначено для хранения миллионов крупных неструктурированных файлов с богатой дополнительной информацией — блоки не содержат метаданных на уровне объекта.
И тут на сцену выходит объектное хранилище S3 – архитектура, основанная на плоской структуре, где каждый файл — это объект, обладающий ключом (уникальным идентификатором), телом данных и набором метаданных. Благодаря такой архитектуре объектные хранилища легко масштабируются до петабайт и выше, активно используют распределённость и репликацию, а также дают возможность гибко хранить и индексировать пользовательские теги. Это делает их идеальным решением для архивов, бэкапов, медиа-библиотек, Data Lake и сценариев, где важна экономичность хранения большого объёма данных и богатая семантика метаданных.
| Критерий | Файловое | Блочное | Объектное |
| Структура | Иерархия папок | Блоки | Плоская |
| Масштабируемость | До десятков ТБ | До сотен ТБ | Петабайты |
| Скорость доступа | Средняя | Высокая | Средняя |
| Метаданные | Базовые | Нет | Расширенные |
| Стоимость за ТБ | Средняя | Высокая | Низкая |
При этом ни один из типов не является абсолютным выигрышем во всех задачах: блочное хранение по-прежнему остаётся лучшим выбором там, где критична задержка и количество IOPS; файловое — для приложений, ожидающих POSIX-совместимости. Современная инфраструктура, как правило, сочетает все три подхода: каждый используется там, где его сила наиболее подходит под требования приложения.
Анатомия S3: бакеты, объекты, метаданные и API
Разобравшись в общей картине, полезно понять внутреннюю условную «анатомию» S3-хранилища.
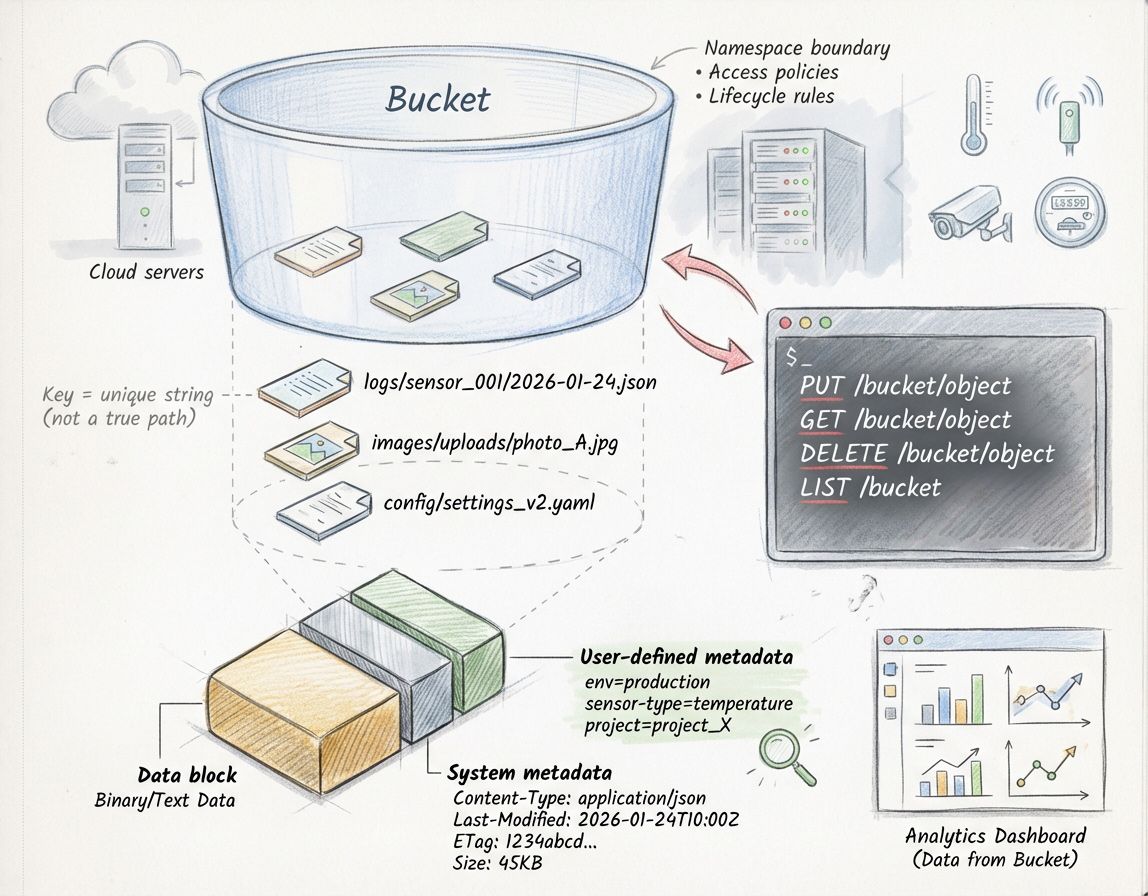
Объект
На уровне модели базовой единицей в S3-хранилище является объект. Объект состоит из собственно данных и набора метаданных. Ключ к объекту часто выглядит как путь, но с технической точки зрения это просто строка, уникальная в рамках бакета.
Метаданные дают огромное преимущество: помимо стандартных свойств типа Content-Type или Last-Modified, можно прикреплять пользовательские теги и атрибуты, которые впоследствии служат для поиска, автоматизации и политики хранения.
Бакет — это логический контейнер в объектном хранилище S3, он задаёт границы неймспейса и уровень, на котором применяются политики доступа, lifecycle-правила и параметры репликации. API S3 основан на HTTP/HTTPS и использует базовые операции PUT/GET/DELETE/LIST, что делает его доступным для большинства языков и платформ через стандартные SDK.
Эта простота взаимодействия — ещё одна причина популярности: приложения могут работать с объектами независимо от того, где именно хранится данные: в публичном облаке, у локального поставщика или в корпоративной инфраструктуре, если система реализует совместимый интерфейс.
Архитектурно реализация S3-совместимого хранилища дополняется системами репликации, версиями объектов, поддержкой классов хранения и механизмами шифрования, что позволяет выстраивать гибкие правила ретенции и управления стоимостью.
Пример: аналитическая платформа получает данные с IoT-датчиков в S3. Через стандартное API платформа забирает данные и строит отчёты, не заботясь о том, где физически лежит объект.
Какие задачи бизнеса решает S3
Если свести преимущества S3 к практическим кейсам, то ясно, что S3 - не просто “облачный диск”, а инфраструктурный слой для управления всеми неструктурированными данными компании.
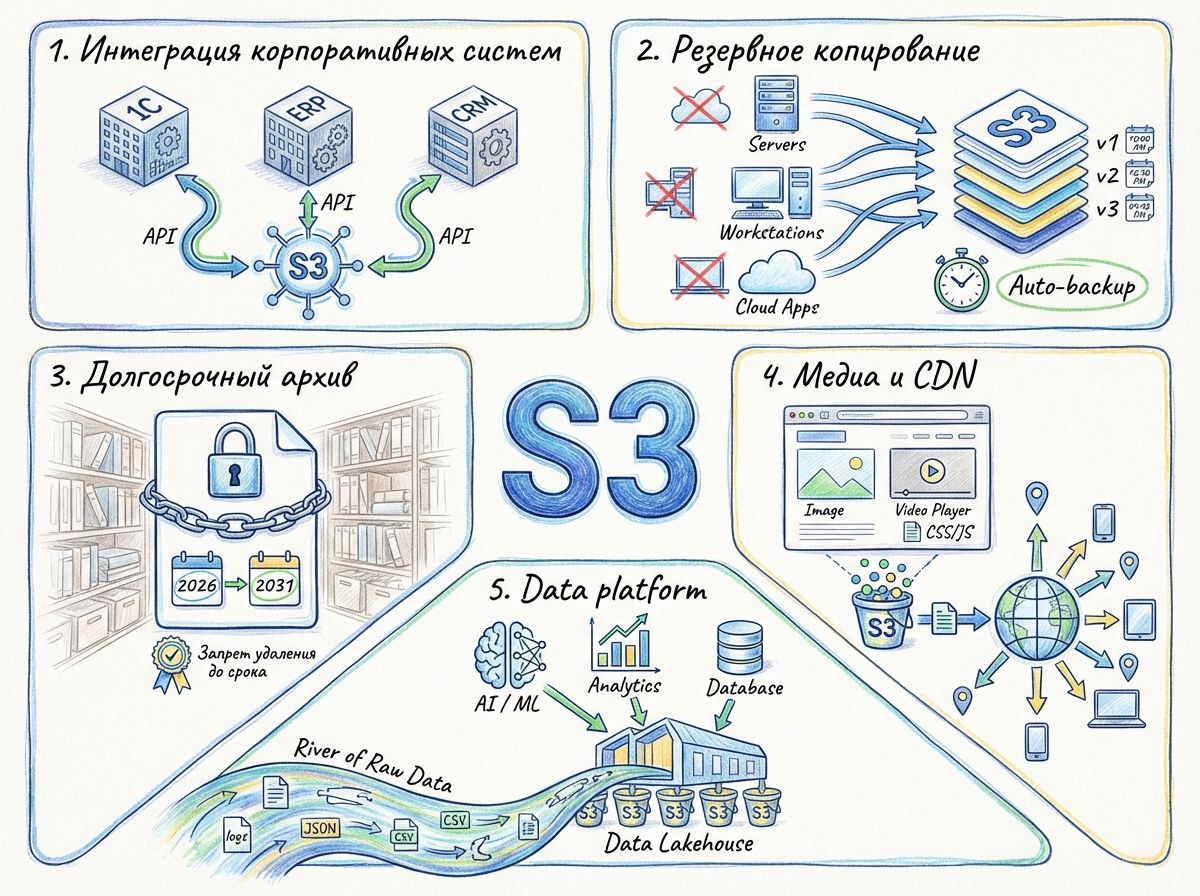
Вот несколько проблем, с которыми сталкиваются российские бизнесы и которые S3 успешно решает:
1. Консолидация данных в S3
Когда данные разбросаны по разным системам (файловые серверы, NAS, FTP), возможны ошибки и сложности с интеграцией. Используя S3, компания получает единый репозиторий, доступный всем системам по стандартизированному API. Это облегчает интеграцию: 1С, системы электронного документооборота, CRM и аналитические платформы начинают работать с единой точкой хранения, что снижает дублирование, упрощает управление версиями и ускоряет процесc поиска. То есть вместо огромной кучи файлов, напоминающей свалку, можно организовать структурированное хранение, поскольку S3 позволяет использовать метаданные.
2. Геораспределенное хранение в S3
Современный бизнес давно перестал быть привязанным к одному месту. Компании работают с клиентами по всей стране, размещают мощности в разных дата-центрах, а их данные рождаются и используются на расстоянии тысяч километров друг от друга. В этой реальности классическая модель централизованного хранилища данных создает две критические проблемы:
- Задержки. Сотрудник во Владивостоке, запрашивающий документ из хранилища в Москве, сталкивается с заметной паузой. Для интерактивных сервисов, потоковой передачи медиа или систем реального времени такие задержки неприемлемы.
- Уязвимость точки отказа. Даже продублированный, но географически сосредоточенный дата-центр остается уязвимым — будь то масштабный инцидент у провайдера, природный катаклизм или региональные ограничения.
Именно здесь геораспределенное S3-хранилище перестает быть просто технологической опцией, а становится стратегической необходимостью. Его задача — представить логически единое пространство для данных, физически разнесенных по нескольким, географически удаленным локациям.
Таким образом, геораспределенное S3-хранилище решает не техническую, а бизнес-задачу первого порядка: обеспечивает скорость, надежность и соответствие требованиям для компании, чья деятельность и ответственность распределены географически.
2. Соблюдение регламентированного срока хранения
Объектные хранилища поддерживают технологию Object Lock, которая позволяет запретить удаление файла раньше срока хранения, что делает возможным соблюдение требований по хранению документов на протяжении нескольких лет.
Смотрите также: Как надёжно хранить документы 5 лет?
3. Data Lake и аналитика
Рост аналитики и проектов ML/AI делает S3 хранилище незаменимым как основу Data Lakehouse: большие наборы необработанных данных хорошо лежат в объектном хранилище и могут быть эффективно подхвачены аналитическими и ETL-пайплайнами. Для отраслей вроде финансов, медицины, ритейла, производства и госсектора выгода особенно очевидна: это и удобство построения архивов под аудит, и экономия при хранении больших объёмов медицинских изображений, и централизованная агрегация IoT-логов.
Таблица 2. Конкретные сценарии применения
| Сценарий | Что даёт S3 |
| Единое хранилище контента | Замена файловых серверов, FTP, сетевых дисков Интеграция корпоративных систем 1С, СЭД, CRM работают с одним хранилищем |
| Резервное копирование | Автоматические бэкапы с версионированием |
| Долгосрочный архив | Хранение документов 5+ лет по требованиям закона |
| Медиа и CDN | Изображения, видео, статика для сайтов |
| Big Data и аналитика | Data Lake / Data Lakehouse для ML/AI проектов |
Классы хранения - как оптимизировать затраты
Одно из ключевых отличий объектного хранилища S3 — наличие классов хранения, которые позволяют оптимизировать затраты без отказа от контроля над данными. Условно их можно разделить на горячий, тёплый и холодный.
● Горячее (Standard): частый доступ, максимальная скорость, дороже
● Тёплое (Infrequent Access): доступ раз в месяц, дешевле хранение
● Холодное (Cold/Archive): редкий доступ, минимальная стоимость
В реальной практике компании часто распределяют объём по классам, ориентируясь на паттерны доступа: например, из 100 ТБ 10 ТБ — активные проекты (горячее), 40 ТБ — завершённые данные и отчёты (тёплое), 50 ТБ — архивы (холодное). В таком сценарии экономия по сравнению с единым тарифом на «горячем» классе может достигать порядка 30–50%, в зависимости от конкретных тарифов и стоимости операций. Самое важное здесь — настроить политики lifecycle, чтобы объекты автоматически переходили в нужный класс по правилам времени жизни и экономили бюджет без ручного вмешательства.

Практический пример: как политика классов хранения экономит бюджет
Представим компанию с 100 ТБ данных. Если все данные хранить в «горячем» классе, стоимость будет максимальной. Но если ввести простую политику: в первую очередь выделить 10 ТБ как «горячие» — данные для активно развиваемых проектов и текущих задач, 40 ТБ перевести в «тёплый» класс после 30–90 дней неактивности, а 50 ТБ держать в архиве с восстановлением по требованию, то итоговая экономия на хранении может достигать 30–40% даже без учёта оптимизации запросов и трафика. При этом нужно учесть, что при восстановлении архива могут возникнуть дополнительные расходы и задержка доступа; поэтому важно просчитать SLA на восстановление для тех наборов данных, которые периодически могут потребоваться. Автоматизация такого перехода через lifecycle-правила снимает человеческий фактор и делает экономию стабильной.
В S3 хранилище ЗАКРОМА.Хранение есть встроенный модуль статистики обращений к объектам, который позволяет использовать метрику ”Давность обращения к объекту, дн.” в политиках жизненного цикла.
Видео: Как настроить тиринг в ЗАКРОМА S3?
Где развернуть S3 хранилище
Облако, on-premise или гибрид: что выбрать?
Решение о физическом размещении данных зависит от множества факторов: регуляторика, требования к контролю, бюджет и желание минимизировать начальные инвестиции.
Публичное облако предоставляет быстрое развертывание и модель «плати по мере роста», но при этом компания частично теряет контроль над фактической физической локацией данных и должна внимательно изучать вопросы локализации. Для организаций, действующих в среде строгих требований по хранению данных или подчиняющихся локальным законам, этот аспект может быть критичным.
On-premise развёртывание даёт полный контроль и помогает соблюдать корпоративные политики безопасности и регуляторные требования, но требует значительных первоначальных инвестиций в инфраструктуру и людей, которые будут её поддерживать.
Гибридный подход часто оказывается наиболее прагматичным: критичные и чувствительные данные хранятся локально, а архивы и менее чувствительные резервные копии выносятся в облако, что сочетает контроль и экономию.
Решение «ЗАКРОМА.Хранение» реализует объектное хранилище S3, которое можно развернуть on-premise хранилища с возможностью настройки гибридного режима, подключая облачный S3 как один из ресурсов хранения. Далее политиками хранения и политиками жизненного цикла определяется удобное место расположения данных.
При выборе модели важно учитывать не только стоимость хранения, но и управление трафиком, время восстановления, хранение ключей шифрования и соответствие законам о локализации данных.
Таблица 3. Варианты развёртывания
| Критерий | Облако | On-premise | Гибрид |
| Контроль над данными | Ограниченный | Полный | Гибкий |
| Начальные инвестиции | Минимум | Значительные | Значительные |
| Соответствие 152-ФЗ | Требует проверки | Да | Да |
| Масштабирование | Мгновенное | Планируемое | Гибкое |
Как выбрать решение - критерии и ловушки
При выборе S3-хранилища подход начинается с проверки технической совместимости.
Ключевые критерии выбора:
Технические:
• Полнота S3 API (процент покрытия методов Amazon S3 API)
• Максимальный размер объекта
• Поддержка версионирования
• Поддержка Object Lock.
• Поддержка мультитенантности.
• Производительность (IOPS, пропускная способность)
• Поддержка георепликации
• Скорость и гибкость масштабирования
Бизнес-критерии:
• Где физически хранятся данные
• SLA и гарантии доступности
• Прозрачность ценообразования
• Возможность бэкапирования
• Наличие в реестре российского ПО, сертификата ФСТЭК
Среди типичных ловушек — vendor lock-in: использование проприетарных расширений API, которые усложняют миграцию; скрытые платежи за исходящий трафик, которые при интенсивной выдаче контента перерастают в существенную статью расходов; минимальные сроки хранения с финансовыми санкциями при преждевременном удалении; и тарификация запросов, которая может резко вырасти, если ваша архитектура подразумевает тысячи мелких обращений к объектам.
Кроме того, для компаний, работающих в российских реалиях, важно обращать внимание на наличие сертификатов и соответствий местным требованиям безопасности и аудита — отсутствие у провайдера необходимых аттестаций превращает даже технически удобное решение в юридический риск.
Выбирать можно по набору требований: где физически хранятся данные, какова модель тарифов, есть ли прозрачность по операциям и egress, поддерживает ли провайдер необходимые требования безопасности и аудита, и как легко будет мигрировать данные в случае смены провайдера. Практический чек-лист для принятия решения включает аудит данных и паттернов доступа, моделирование TCO с учётом операций и трафика, тестовую миграцию для проверки интеграции, настройку lifecycle и версионирования, и прописанную стратегию восстановления. Все эти пункты стоит отработать в виде реальных тестов и отчётов до принятия масштабного решения о переносе терабайтов информации.
Чек-лист при выборе:
• Данные хранятся в России
• Есть аттестация по 152-ФЗ
• Понятная модель тарификации
• Возможность миграции без потерь
Заключение
Объектное хранилище S3 — это не просто технологический тренд, это архитектурный подход. Он меняет принципы хранения и управления данными: упрощает интеграцию, снижает расходы, позволяет масштабировать и строить надёжные процессы хранения.
Главное — оценивать реальные требования бизнеса, моделировать расходы с учётом операций и трафика, и комбинировать объектное хранение с блочным и файловым там, где это оправдано. Тогда объектная модель станет вашим стратегическим инструментом для работы с данными на годы вперёд.
Если вам требуется локальное S3-хранилище с полным контролем и соответствием российским требованиям, предлагаем обратить внимание на решение «ЗАКРОМА.Хранение»— объектное хранилище S3, которое ориентировано на развёртывание в собственной инфраструктуре и позволяет сочетать гибкость S3-модели с требованиями контроля и соответствия российским стандартам аттестации.