Масштабирование объёма хранения
При росте объема хранения масштабирование может быть осуществлено на двух уровнях:
- На уровне дисковой подсистемы (zds)
- На логическом уровне за счёт добавления дополнительных ресурсов хранения.
Первый способ может быть ограничен серверной инфраструктурой: например, возможностью подключить диск(и). Второй способ, напротив, не ограничен и может быть всегда использован.
Масштабирование на уровне дисковой подсистемы
Следует учесть, что технология помехоустойчивого кодирования Erasure cooding не позволяет изменять соотношение частей данных и частей избыточности (data/parity) после начала использования. Поэтому при использовании в качестве ресурса хранения zds (Zakroma data storage) физические диски можно объединять в volume group и логические вольюмы (lvm) для упрощения процедуры увеличения размера без необходимости изменения конфигурации ZDS. Но в таком случае возможно только кратное увеличение дисков. Если использовать ZDS в режиме EC поверх RAID массива, то возможно увеличение от 1 диска на сервер. Так же возможно увеличение объема хранение через увеличение числа volume в конфигурации ZDS в случае подключения новых дисков.
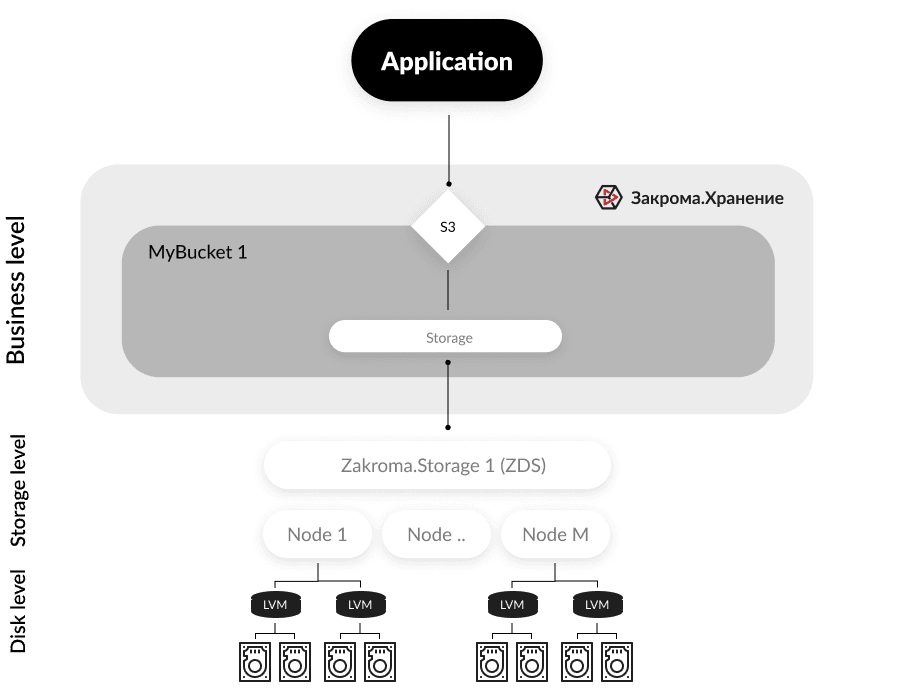
Применение этого метода не требует использование механизмов приложения, т.к. происходит на уровне нижележащей инфраструктуры и может быть произведено по инструкции используемых для этого сторонних компонент.
Масштабирование на логическом уровне (приложения)
В любой момент можно расширить ёмкость хранения за счет добавления нового ресурса хранения (хранилища) и подключения его как новую группу хранения бакета.
Например, при использовании кластера zds в качестве основного хранилища данных бакета, при невозможности его расширения, вы можете создать второй кластер zds и подключить его в тот же бакет. Для S3-клиентов будет доступен суммарный объём двух кластеров таким образом, как если бы он был единый.
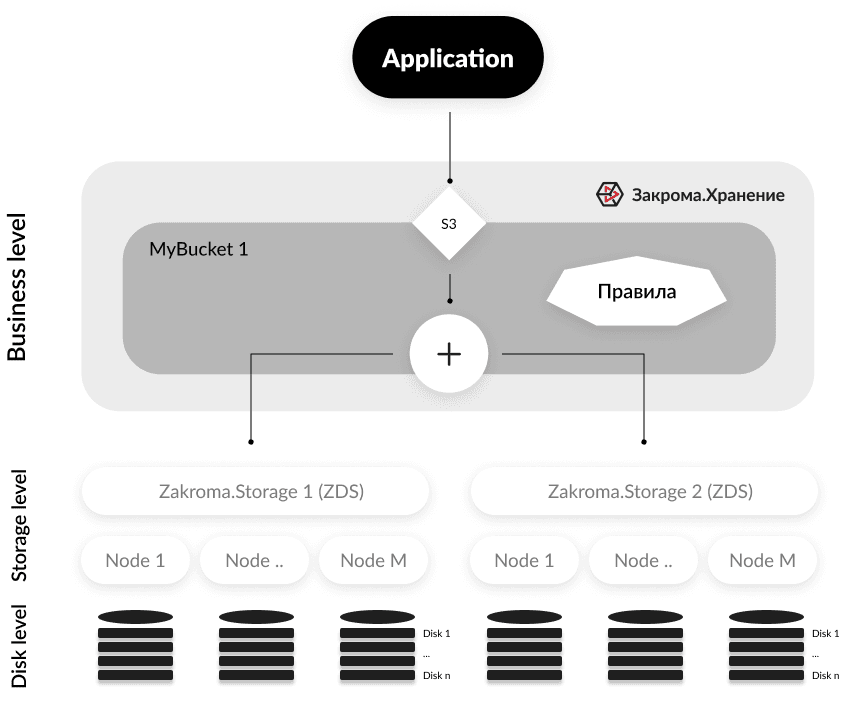
Для увеличения размера ёмкости хранения бакета в административной веб-консоли:
- Хранилища на странице
Хранилища - Откройте вкладку
Настройка хранениябакета. - Нажмите кнопку
+ Добавить группу хранения - Выберите созданное на первом шаге хранилище и укажите путь в нём (при необходимости, иначе будет использован корень файловой системы).
- При необходимости укажите ограничение на максимальный объём хранения для других групп хранения в параметрах группы. Это свойство учитывается для автоматического выбора при загрузке объекта вместе с приоритетом группы хранения (порядком следования в настройках хранения бакета).
Классы хранения
При этом подключаемое хранилище может быть того же или другого типа. Также это позволяет с помощью политик Жизненный цикл настроить оптимальное распределение объектов по подключенным хранилищам, относясь к ним как к классам хранения.
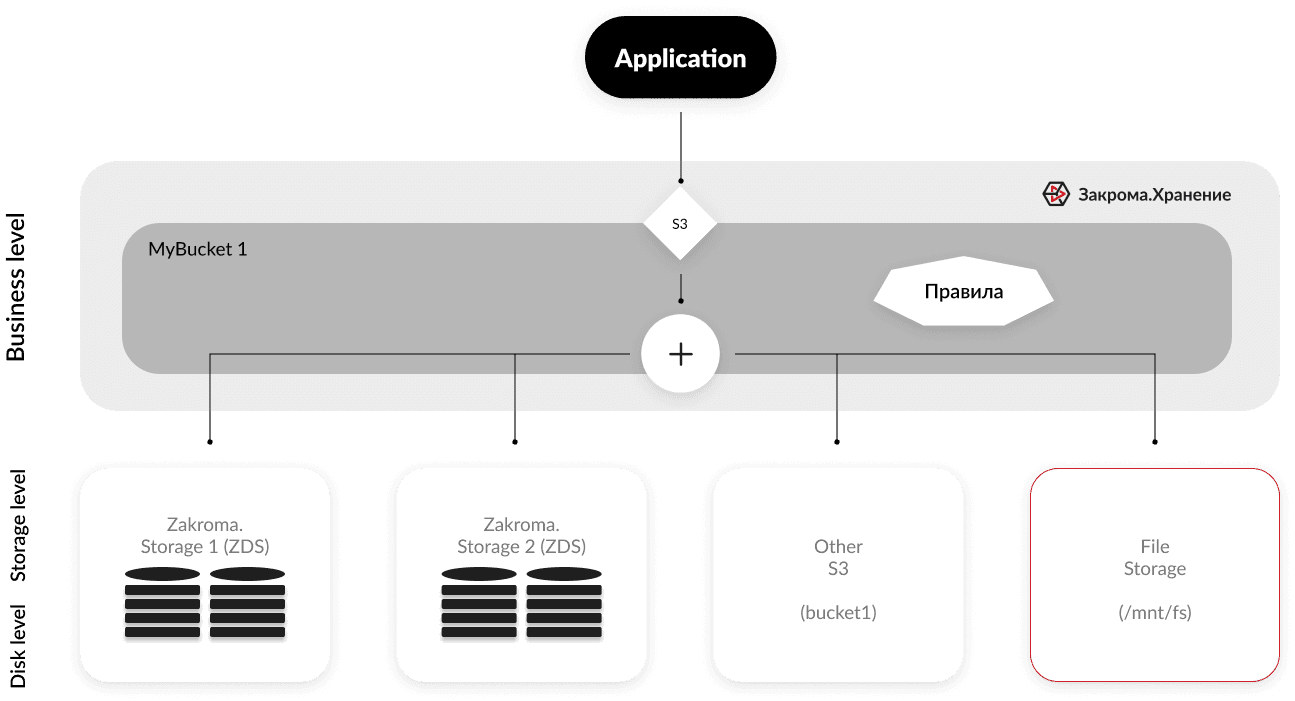
Масштабирование объема метаданных
Для хранения объектов в системе требуется объем метаданных, который может быть распределен между несколькими шардами. Это позволяет масштабировать количество операций чтения и записи. При увеличении количества объектов в системе требуется увеличение объёма под хранение метаданных. В этом случае можно добавлять новые шарды в систему, посредством изменения конфигурации. В качестве шардов можно использовать как новые схемы в существующих базах данных, так и новые базы данных.