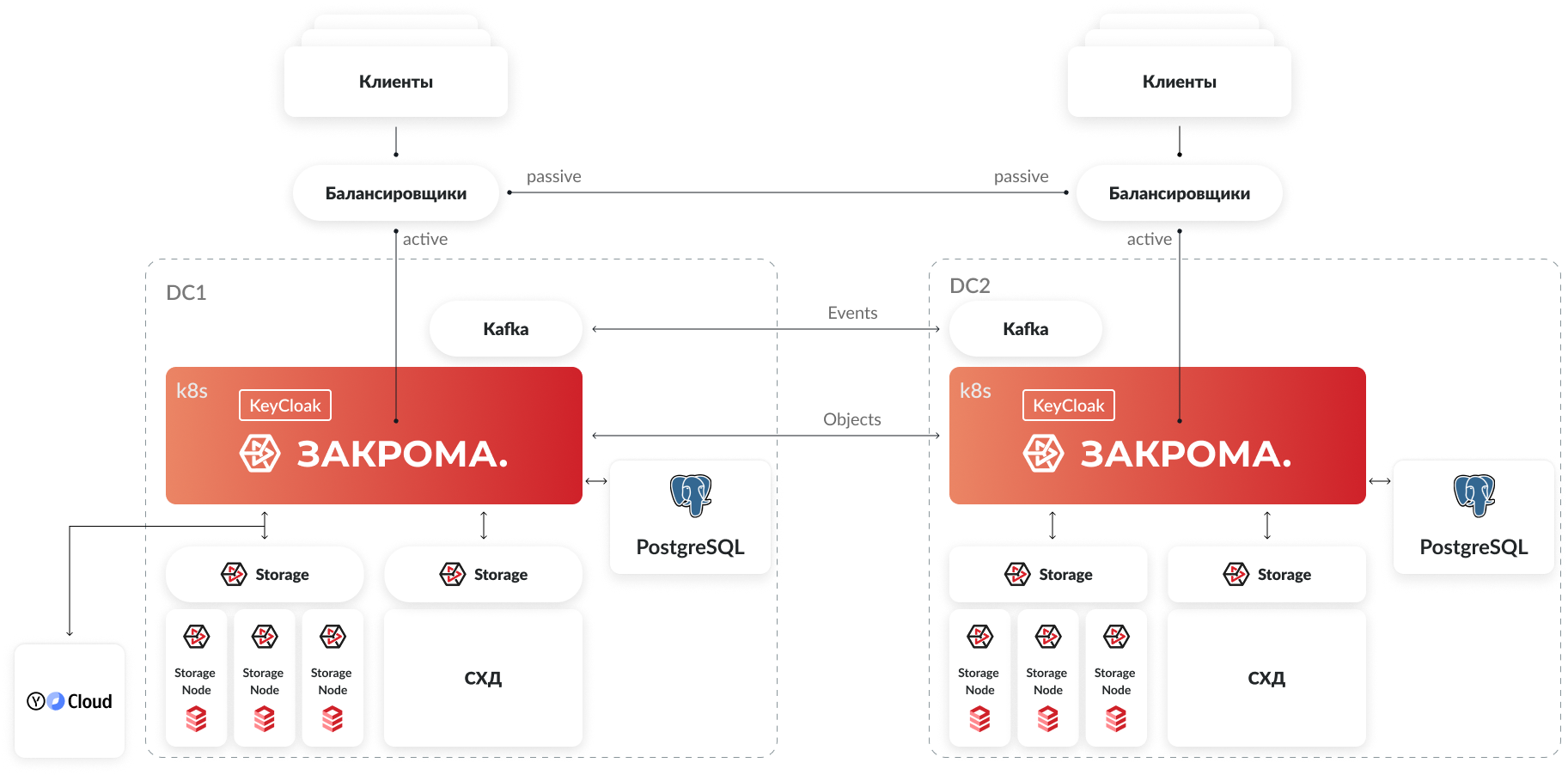
Мультикластер
Общий принцип работы
МультикластерМультикластер — это режим работы Закрома.Хранение, при котором несколько инстансов системы объединяются в распределённое хранилище.
Такой подход повышает надёжность, масштабируемость и позволяет построить собственный CDN.
Мультикластер обеспечивает высокую доступность: при отказе одного из узлов его функции автоматически берут на себя другие узлы системы. Благодаря аппаратной избыточности бизнес-сервисы и приложения продолжают работать без перерывов. Для построения отказоустойчивой архитектуры требуется как минимум два физических сервера, оснащённых системами хранения данных.
Каждый узел кластера представляет собой отдельный инстанс системы ЗАКРОМА.Хранение, который принимает и передаёт события другим кластерам, обеспечивая согласованность данных в распределённой среде. У каждого узла своя собственная база данных. Kafka может быть как общей для всех узлов, так и индивидуальной для каждого — при условии корректной настройки топиков.
Включение кластерного режима
Для включения кластерного режима необходимо подключить Kafka и настроить конфигурацию. Для более подробной настройки смотреть здесь.
Создание рабочей области в кластерном режиме
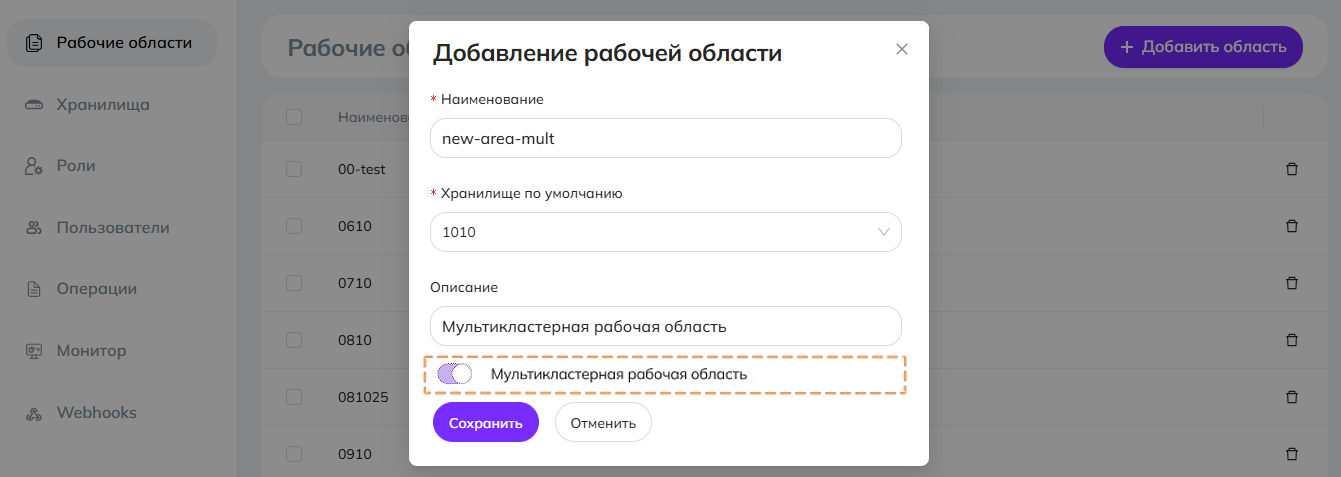
Обычно рабочая область создаётся в соответствии с инструкцией создания рабочей области. Чтобы сделать рабочую область мультикластерной, необходимо активировать параметр «Мультикластерная рабочая область».
В мультикластерной области объекты всех бакетов автоматически реплицируются. В обычной рабочей области репликация объектов не осуществляется.
Обратите внимание, что при создании рабочей области, полученной из другого кластера, хранилище по умолчанию не устанавливается автоматически. Для корректной работы бакетов необходимо вручную настроить Политику хранения.
Отображение мультикластерной рабочей области
В списке всех рабочих областей мультикластерная рабочая область отличается от обычной рабочей области специальным символом, расположенным справа от ее названия.
При наведении на символ, отображается подсказка «Мультикластерная рабочая область».
В карточке рабочей области мультикластерная рабочая область имеет переключатель «Мультикластерная рабочая область»
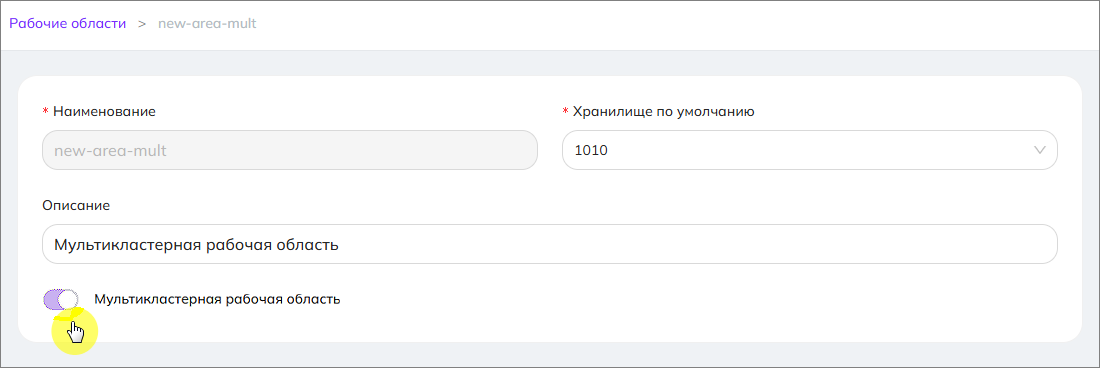
Переключатель всегда находится в заблокированном состоянии, так как изменить этот параметр после создания рабочей области невозможно.
ВажноПри создании рабочей области в другом кластере, в текущем кластере автоматически создаётся рабочая область с пустым хранилищем по умолчанию. Если после этого вы не задали хранилище по умолчанию вручную, то для возможности загрузки файлов на текущий кластер необходимо настроить политику хранения вручную — для бакета, созданного в другом кластере. Для бакетов созданных в текущем кластере действуют обычные правила создания политик хранения, при условии, что в рабочей области задано хранилище по умолчанию.
Создание бакета в кластерном режиме
Создание бакета в мультикластерном режиме не отличается от обычного создания бакета.
Политика хранения в другом кластереОбратите внимание: при получении события о создании бакета из другого кластера, система проверяет наличие хранилища по умолчанию в текущей рабочей области.
- Если хранилище по умолчанию задано — автоматически создаётся политика хранения, привязанная к нему.
- Если хранилище по умолчанию не задано — политика хранения не создаётся, и локальное хранение отсутствует.
В этом случае, при попытке пользователя скачать файл из такого бакета, загрузка будет происходить с удалённого кластера. Это поведение сохранится до тех пор, пока для бакета не будут вручную добавлены политики хранения.
Отображение мультикластерного бакета
В списке бакетов рабочей области мультикластерный бакет отображается со специальным символом, расположенным справа от его названия.
При наведении на значок появляется подсказка «Мультикластерный bucket».
Для каждого кластера политики хранения индивидуальны и настраиваются под каждый кластер отдельно.
Права, роли и s3 токены
В режиме кластера выполняется синхронизация ролей, прав доступа к рабочим областям и бакетам, а также s3-токенов для подключения к Закрома.Хранение (aws_secret_access_key).
Генерация токенов выполняется на вкладке «Пользователи».
Обмен данными между кластерами осуществляется через топики Kafka.
Обмен сообщениями между кластерами, cинхронизация
Обмен сообщениями между кластерами происходит при помощи Kafka(распределённый программный брокер сообщений).
Добавление нового узлаПри добавлении нового узла выполняется чтение всех сообщений из топиков Kafka, что обеспечивает консистентность данных для нового узла, а также восстанавливает актуальное состояние на уже существующих узлах, где ранее произошёл сбой (например, из-за потери интернет-соединения).
Важно
При создании нового узла необходимо учитывать два момента:
- Топик Kafka не является бесконечным — сообщения в нём периодически удаляются в соответствии с настройками хранения.
Если важное событие было удалено (например, создание бакета), а последующие события (загрузка файлов в этот бакет) остались, это может привести к неконсистентности данных.- Для каждого нового узла требуется уникальная consumer group.
Перед добавлением узла убедитесь, что вы просмотрели существующие consumer group в Kafka и указали новое имя — иначе чтение топика начнётся не с начала, и часть событий будет пропущена.
Кластерные вольюмы (Cluster Volume) и Ссылочные объекты
ГлоссарийСсылочный объект — это объект, который не хранится физически в текущем кластере, но содержит ссылку на оригинальные данные, размещённые в другом кластере. Ссылочный вольюм (Cluster Volume) — это ссылка на раздел хранилища бакета, расположенный на другом узле мультикластера.
Ссылочный объект создаётся, когда на другом кластере загружается объект, но в текущем кластере либо не настроена политика хранения, либо объект ещё не успел физически отреплицироваться на узел мультикластера. В этом случае файл существует на другом кластере, и при необходимости его можно получить оттуда по ссылке.
Для поддержки ссылочных объектов при создании бакета формируются ссылочные вольюмы (Cluster Volumes), которые указывают на соответствующие узлы мультикластера.
Синхронизация файлов между кластерами
Синхронизация, а точнее — получение файлов с другого кластера и их сохранение в локальном хранилище, выполняется только в том случае, если к бакету привязано как минимум одно локальное хранилище (то есть настроена политика хранения).
Скачивание объектов
При скачивании объекта текущий кластер выполняет поиск файла по следующему алгоритму:
- Если файл уже присутствует в локальном хранилище, кластер отдаёт его напрямую.
- Если файл не найден (например, ещё не завершилась репликация), используется ссылочный объект, и выполняется попытка загрузки из другого кластера.
- Если у объекта есть несколько ссылок на другие кластеры, система последовательно обращается к каждому из них, пока не получит успешный ответ или не проверит все узлы мультикластера.
Механизм обрывания циклов
Чтобы предотвратить зацикливание при скачивании объектов, используется механизм обрывания циклов. Он отслеживает повторные запросы и прерывает обработку, если текущий запрос уже был выполнен данным кластером.
Загрузка объектов
Загруженные объекты в текущем кластере автоматически реплицируются на другие кластеры, если бакет работает в режиме «Мультикластерный bucket».
При загрузке объекта событие фиксируется в очереди сообщений Kafka. Другие кластеры считывают это сообщение и загружают объект в свои локальные хранилища.
Важно убедиться
Перед загрузкой объектов в новый бакет убедитесь, что бакет успел отреплицироваться на другие кластеры. В противном случае существует риск, что событие загрузки будет обработано другим кластером раньше, чем событие создания бакета, что может привести к ошибкам репликации.